|
凤凰网科技讯 6月4日, 近年来,多模态大模型(MLLMs)在图像、视频等视觉语言任务上取得了显著进展,但在部分场景任务上却亟待提高。一个突出的挑战是模型在三维空间感知与交互(空间智能)方面存在明显瓶颈,例如在需要精确定位物体的机器人抓取任务或依赖复杂空间推理的具身智能任务中表现不足。与此同时,评估模型对视频内容理解的现有标准也存在局限,难以全面、精准地衡量模型对动态场景、复杂时空关系等关键要素的掌握程度。 面对这些挑战,香港中文大学计算机科学与工程学系的视觉与语言实验室(CUHK LaVi Lab),在王历伟教授的带领下,LaVi团队开启了全新的思考和探索,提出“3D即视频”的全新学习范式,探索如何从海量视频中直接学习三维空间先验知识以增强模型的空间智能,近期在这一方向上取得了重要突破。 与此同时,针对多模态大模型在视频内容理解与评测方向面临的效率、覆盖度和时效性的难题,LaVi团队正与凤凰卫视旗下人工智能数据服务机构凤凰智媒展开深入合作,共同构建一个更全面和动态的视频理解评测框架。 用视频思维重构3D认知
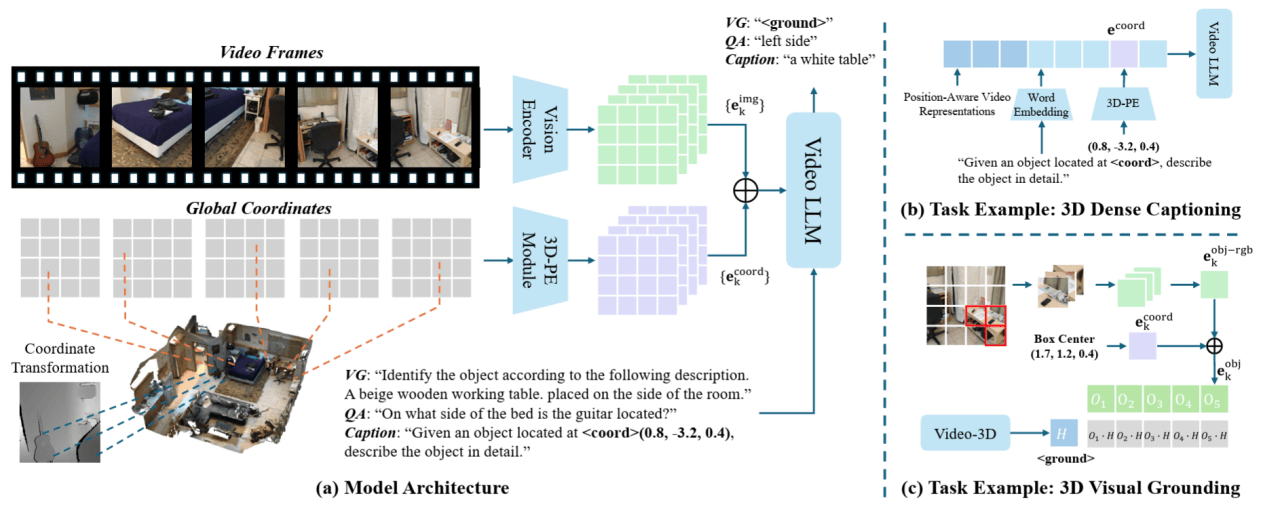
【图1: 图片来源于CUHK LaVi 实验室于国际知名人工智能会议CVPR 2025上发表的论文 Video-3D LLM: Learning Position-Aware Video Representation for 3D Scene Understanding[1]】 2024年底, 王历伟教授带领研究团队提出“3D即视频”的全新学习范式,提出了Video-3D LLM的模型架构, 如图1所示。将3D场景的时序视频流作为多模态大模型的输入,以保留时空连续性,同时通过获取区域(patch)精细级别的全局坐标而构建三维空间位置编码(3D-PE),将3D位置编码注入到视频帧的视频特征中。 为了提高学习的效率,还设计了巧妙的方法来智能地选取关键帧,相比均匀采样计算成本降低一半。不仅于此,团队还提出了多任务统一架构模型支持视觉定位、密集描述、问答等任务端到端训练。 Video-3D LLM在ScanRefer、Multi3DRefer等五大3D场景理解基准测试中实现全面突破。该方法在3D数据利用方面表现出极高的效率,为机器人、自动驾驶等领域的空间认知任务提供新范式团队已将代码开源 [1],并发布详细训练方法,有望加速具身智能时代的到来。 突破传统范式:从视频中学习三维空间先验知识 多模态大模型(MLLM)遇上3D场景理解,传统方法都绕不开一个"硬门槛"――需要显式的密集3D数据输入,如点云、深度图或鸟瞰图。这不仅增加了数据获取成本,更限制了模型在日常生活中的应用场景。近几个月来, LaVi团队继续在探索空间智能学习新范式的这个方向上前进突破。王教授和团队提出一个直击本质的问题:能否让多模态大模型直接从视频中学习3D几何先验? “视频相比三维空间的各种数据来说,是更容易获取的。如果能从视频中学习得到大量对三维空间感知有帮助的信息,将给具身智能,空间智能等方向的研究带来新思路。”王教授介绍到。 LaVi团队近期发布在arxiv的Video-3D Geometry LLM (VG LLM)论文【2】中提出的模型仅凭视频输入即可在多项3D场景理解任务中足以比肩利用了3D输入的各类前沿方法,甚至以4B参数量在权威的空间推理基准VSI-Bench上超越谷歌的Gemini 1.5 Pro! Video-3D Geometry LLM前瞻性地在多模态大模型中引入了一个3D先验编码器。该模块对视频中多帧图像的对应关系进行建模,从视频序列中提取隐含的3D几何特征,与传统视觉特征融合后输入大模型。这种学习得到"几何特征先验"的策略,使模型无需任何显式3D输入即可建立空间认知。与此同时, 通过跨模态特征融合,即在图像块维度建立几何-语义关联。这种融合策略使视觉特征天然携带3D空间先验知识,为下游任务提供联合表征基础。该方法实现了坐标系统一性建模,以首帧坐标系为基准,在无相机参数条件下构建跨帧空间关联,实现跨帧空间一致性理解。
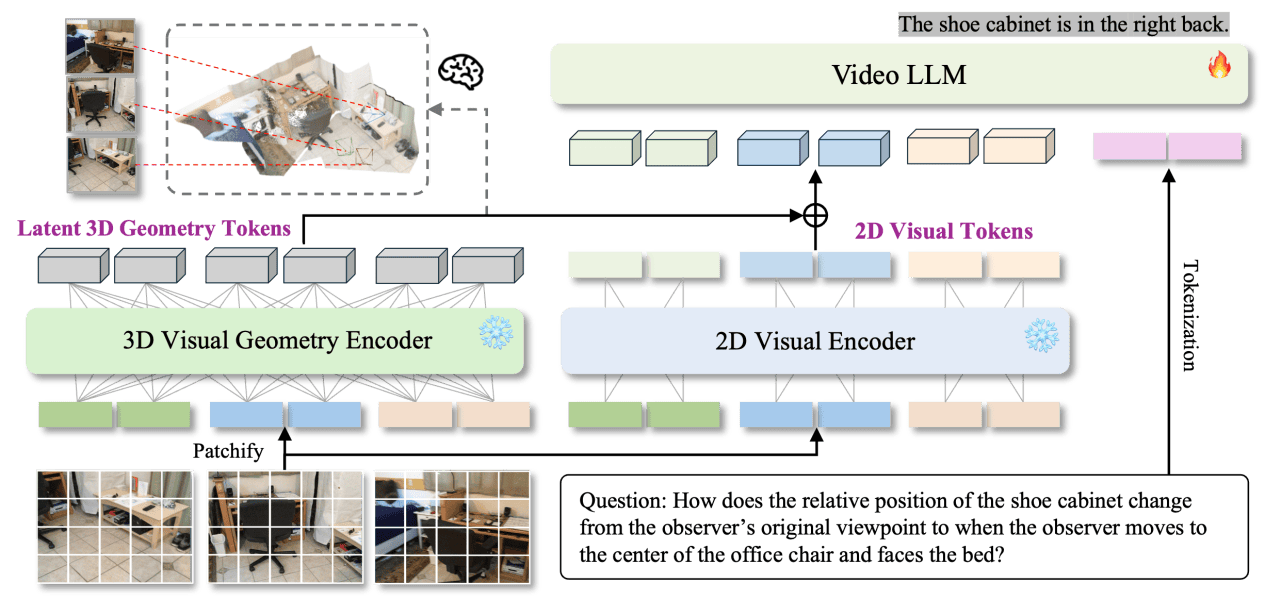
【图2 : CUHK LaVi Lab 团队近期发布的方法 Video-3D Geometry LLM 【2】】 基于这些设计,该方法能够应用到不同的3D理解任务以及空间推理任务之中,如 3D视觉定位,3D密集描述生成,3D视频物体检测任务等。 相较于传统方法,摆脱了传统方法对相机参数或者输入的三维数据的依赖,直接从视频输入预测完成三维空间智能任务。
【图3: VG LLM【2】在三维视觉定位任务中的可视化结果。模型可以根据视频流识别出文本描述的对象出现的帧编号以及其在当前帧下的有向三维边界框。该图中展示了视频、模型预测的有向三维边界框(用绿色标出)、以及真实的三维有向边界框(用蓝色标出)。如图所示,VG LLM模型能仅仅根据视频输入就可以有效地识别出“远离”、“对面”、“旁边”等空间关系。】
【图4: VG LLM【2】在三维视频对象检测中的可视化结果。模型可以根据视频识别出视频中所有出现的对象在同一坐标系下的有向三维边界框。如图所示,模型能够有效地检测出不同粒度的对象,包括水池、垃圾桶、开关等,并能输出其在统一坐标系下的位置。】 轻量模型表现媲美顶尖方案。在涵盖3D视觉定位、密集描述、空间推理等任务的全面测试中,4B参数的Video-3D Geometry LLM展现出惊人实力。 例如在3D视觉定位任务中,通过将3D定位转化为视频时空定位,在不依赖点云数据并直接预测有向3D边界框的设定下,取得了优异的效果。这揭示了3D视觉定位可以有效的通过视频定位的新范式解决. 最令人瞩目的是在空间推理权威基准VSI-Bench上,VG LLM的平均得分甚至超越了Gemini 1.5 Pro、GPT-4o等商业大模型。这意味着,在理解"左转三米后的视角"这类复杂空间转换问题上,轻量化小模型首次展现超越商业大模型的潜力。 关于未来的研究方向,王历伟教授表示,港中大LaVi团队会继续沿着从视频中学习和提高多模态模型的空间智能。 “视频是人们平时获取信息的丰富载体,大模型从视频中不仅可以获取内容知识,也有望学习探索出来一条不一样的空间智能和具身智能的道路。而这样的探索也有希望让空间智能和具身智能学习的数据成本和采集设备依赖都会不断下降,也有利于提高场景泛化的能力。” 视频理解需要更全面和动态的评测框架 “ 当前人工智能多模态大模型对于视频的理解还远远不足,为了促进领域对视频语言的研究,我们需要有一个更加全面和动态的评测框架。 ” 现有的视频语言评测基准通常依靠纯人工标注,成本高昂且难以扩展。尤其是当研究者越来越重视评测多模态模型的视频理解能力时,传统方法长视频(比如小时级别的视频)的标注工作更是昂贵且繁琐。这给学术界和工业界提出了一个亟待解决的难题:如何以高效、低成本的方式构建一个动态的视频语言评测基准? 目前, 王历伟教授带领的LaVi 团队正在和凤凰卫视旗下人工智能数据服务机构凤凰智媒团队在构建全面、动态的评测视频理解能力的方向上展开合作探索。 鉴于视频数据的信息丰富但又很多冗余的特点,研究团队首先提出了一种全新的视频语言表征。该表征采用了一种富含语义特征的分层结构,包括了场景级别和对象级别的特征。具体来说,研究团队利用先进的视觉基础模型,实现了对视频中的场景信息和对象信息的自动化提取,形成了对象级别和场景级别的特征表达。传统的视频评测的问答数据,通常需要依赖于人工标注,尤其在处理小时级别的视频时,这种传统流程面临着成本高昂和难以扩展等挑战。研究团队的方法可以自动地实现从视频输入到问答对的高效构建。该流程充分利用了上述的全面且紧凑的视频特征,通过视觉提示等方式引导大模型自动生成问答对和进行自我验证,同时辅以人工修正以确保数据质量。研究团队的实验结果表明,这样的自动化评测数据的生成方法在保证数据质量的前提下将测试平台准备评测数据的成本降低了超过七成,这使得以高效、低成本的方式从零开始构建一个可扩展的视频语言评测基准成为可能。 凤凰卫视拥有以多模态、多语言和多元文化为特色的高质量内容数据,目前已构建一套完整的端到端技术能力,覆盖文本、音频、视频、图像等多模态数据的精细化加工能力服务于人工智能场景。因此,可以基于凤凰卫视不断更新的视频源信息来自动化动态地构建视频问答的评测基准。“因为数据评测需要是动态的,每隔一段时间,测试题目都是自动生成的,且是全新的,因此这个也可以从最根本的数据层面尝试解决模型评测时大模型数据污染的问题”。同时,王教授也提到,双方联合推出的多模态视频理解评测平台还将于近期开放一部分视频数据给学术界,希望能够促进不仅仅是视频理解,还有视频编辑与生成等方向的研究进展。 从视频中学习空间智能带来未来的无限畅想;构建视频评测基准又着眼于解决当前多模态大模型视频理解的许多重要问题。相信港中大LaVi团队会不断地在多模态研究上取得研究突破。 引用链接: https://github.com/LaVi-Lab/Video-3D-LLM https://lavi-lab.github.io/VG-LLM/ (责任编辑:刘畅 )
【免责声明】本文仅代表作者本人观点,与和讯网无关。和讯网站对文中陈述、观点判断保持中立,不对所包含内容的准确性、可靠性或完整性提供任何明示或暗示的保证。请读者仅作参考,并请自行承担全部责任。邮箱:news_center@staff.hexun.com |


1 小时前

1 小时前

1 小时前

1 小时前

1 小时前


格隆汇6月6日|日本内阁官房长官林芳正在周五的例行新闻发布会上说,正在评估中美元首

格隆汇6月6日|越南统计局:越南5月出口额同比增长17%,达396亿美元。越南5月CPI同比

对冲基金大鳄、潘兴广场资本管理公司CEO比尔・阿克曼在帖子中表示支持特朗普和马斯克

特朗普前高级顾问班农建议总统签署行政命令接管SpaceX,引发马斯克的愤怒回应。

6月6日,2025中国汽车重庆论坛以“在变革的时代塑造行业的未来”为主题举行。长安汽车

每经记者|曾子建每经编辑|肖芮冬 6月6日早盘,港股市场窄幅震荡。截至发稿前,恒

市场对经济前景看法难言好转,白银并无充分理由独立快速上涨,金银比或有向上修复空间

2025年中国汽车重庆论坛于6月6-7日举行,主题为“在变革的时代塑造行业的未来”。中国

每经编辑|杜宇 6月5日,现货白银一度大涨4.5%,触及每盎司36美元整数关口上方,创

港股黄金股集体拉升,其中,中国白银集团大涨近14%领衔,紫金矿业涨3.2%,潼关黄金、